
この記事では、REST APIとGraphQLの歴史を振り返りつつ、GraphQLがRESTのどのような課題を解決するのかを分かりやすく解説していきます。
「APIの歴史について知りたい方」「GarphQLを使うことのメリットをサクッと知りたい方」の参考になれば幸いです。
では始めます!
TL;DR
時間がない人向け。
- REST以前のAPIの歴史
- 1960年代にRPCが登場
- 1999年に登場したのがSOAP
- その後に登場したのがREST
- RESTの課題
- 不要なデータまで取得する
- 必要なデータを得るために何度もRequestを送る必要がある
- エンドポイントが増え続けるため管理が大変
- GraphQLの歴史
- GraphQLはRESTの課題を解決するためにFacebookによって開発された
- 2015年にオープンソース化
- GraphQLのメリット
- 一つのクエリで過不足なくデータを取得できる
- 欲しいデータを直接指定できるので分かりやすい(記述しやすい)
- エンドポイントの管理が不要
- 強力な型システム
- GraphQLのデメリット
- 学習コストが高い
- complexityやN+1問題など、適切な対処ができないとセキュリティやパフォーマンス面で落とし穴になる場合がある
- RESTに比べて歴史が浅いためまだ情報は不足している
APIの歴史(REST以前)
まずはAPIの歴史を振り返っていきます。
実はREST以前にもAPIは存在していました。以下で順に紹介していきます。
RPC(Remote Procedure Call)
1960年代に開発されたのがRPCです。
RPCは分散システムの実現を目的として作られた技術で、RPCを使うことで遠隔のサーバーで実行している処理をクライアントから呼び出すことができます。
RPCのプロトコルは互換性のない多くのバリエーションが存在しており、それらの統一を目指して、多くのプロトコル(XML-RPC、JSON-RPC など)が誕生しました。
SOAP(ソープ)
1999年にマイクロソフトによって開発されたのが、SOAPです。
SOAPはXML-RPCの拡張です。
※XML-RPC:RPCのバリエーションの一つで、XMLを送信することで処理の実行を要求するプロトコル
SOAPはHTTPプロトコル上でXML形式のメッセージを通信することで、サーバー側から必要なデータを取得することができます。
高機能ではあるものの、仕様が複雑で扱いづらいことから現在ではほとんど使用されていません。
REST
REST(Representational State Transfer)は、ロイ・フィールディング(当時カリフォルニア大学アーバイン校の大学院生で、HTTPプロトコル規格の主要著者の一人)が執筆した2000年の博士論文で紹介されました。
当初はSOAPとRESTに関する論争が巻き起こっていたようですが、AmaoznがSOAP製とREST製のWeb APIを出し、ユーザーの利用比率が2:8になったことで論争に終止符が打たれたようです。
その後は瞬く間にRESTが普及し、現在では最も使用されるWeb APIになっています。
RESTはURIが「情報」に対応しており、例えば以下のエンドポイントにリクエストを送信すると、それぞれ固有の(必要なデータ情報を含んだ)レスポンスを返します。
- /api/hoge/1
- /api/fuga/2
このように、データモデル毎に必要なエンドポイントを複数用意する手法は、現代のWeb開発に慣れている人にとっては馴染みの深いものでしょう。
というより、この方法が「当たり前」となっているエンジニアも多いと思います。
しかし、このRESTには、いくつかの「課題」が存在しています。
次にその課題を紹介していきます。
REST APIの課題について
とてもシンプルで扱いやすく、現在では完全に普及しているRESTですが、複雑な要件を持ったアプリケーションが増えるにしたがって課題も見えてきました。
- オーバーフェッチング(過剰な取得)
- アンダーフェッチング(過小な取得)
- エンドポイントの管理負荷が高い
以下でそれぞれ説明していきます。
オーバーフェッチング(過剰な取得)
一つ目は、オーバーフェッチング(過剰な取得)です。
これは要は、「使用しない不要なデータまで取得してしまう」ということです。
例えば、以下のエンドポイントを叩いた場合に、ユーザーの「年齢」「名前」「性別」「メールアドレス」「自己紹介」のデータが返るとします。
/api/user/1
しかし、画面ではユーザーの「名前」しか表示する必要がない場合、他のデータ(年齢・性別・メールアドレス・自己紹介)は無駄になってしまいます。

このような、取得するデータの無駄は、通信やサーバーサイド側での負荷の増加につながってしまうため、RESTの課題の一つとなっています。

アンダーフェッチング(過小な取得)
オーバーフェッチングと同時にアンダーフェッチング(過小な取得)も課題の一つとして挙げられています。
これは要は、「一回で必要なデータが取れない場合、複数回APIを叩く必要がある」ということです。
例えば、以下のようにユーザー情報と投稿情報を返すエンドポイントがあって、両方のデータがアプリケーションの画面表示に必要な場合、二つのエンドポイントに対してリクエストを送る必要があります。
- /api/user/1
- /api/post/1
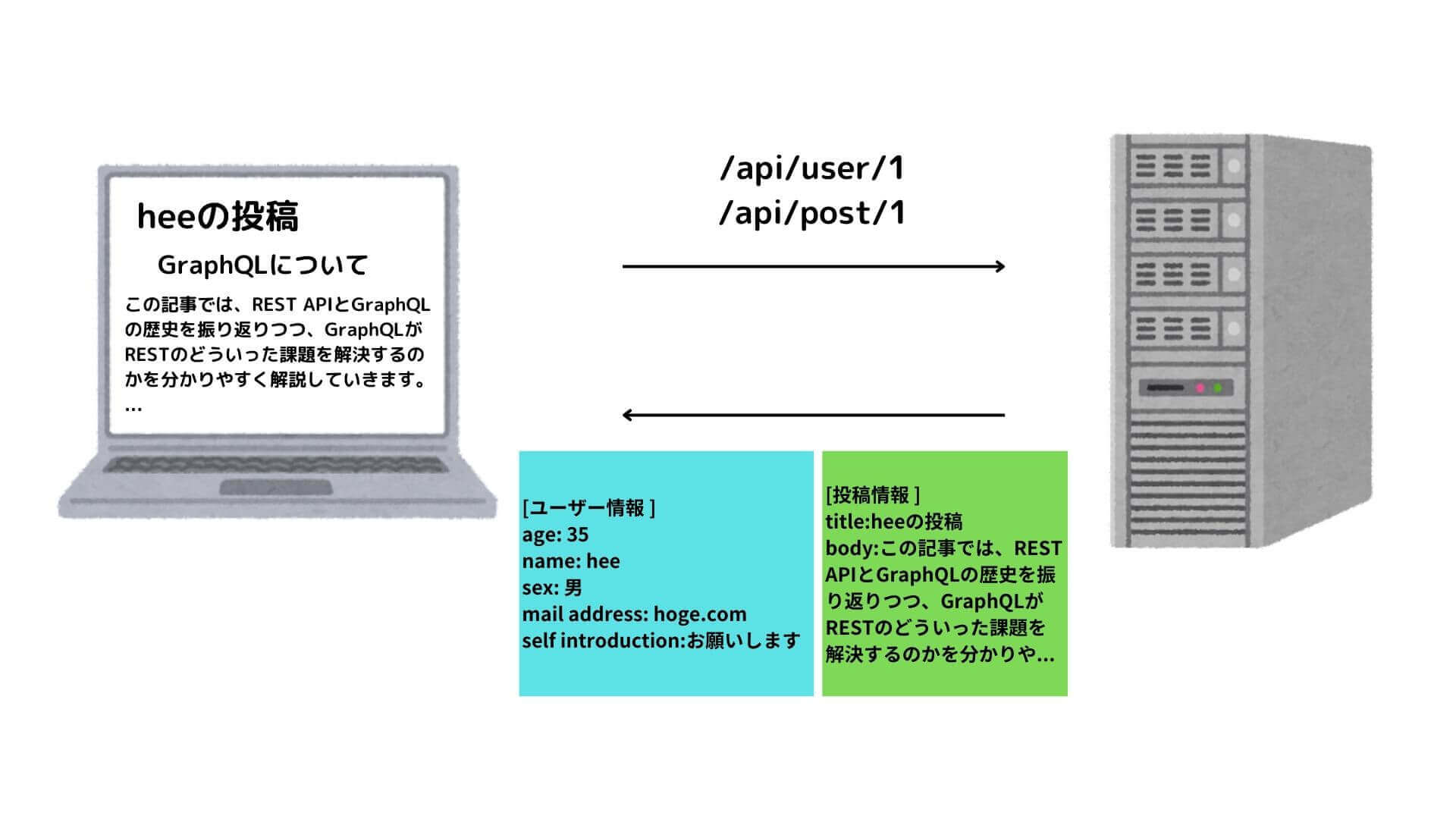
APIの通信量(回数)が増えるほど画面表示までに時間がかかる上に、通信の負荷も上昇するため、RESTの課題の一つとなっています。
エンドポイントの管理負荷が高い
上記の「オーバフェッチング」や「アンダーフェッチング」を解消する方法があります。
それは、ユースケース毎にエンドポイントを作成することです。
例えば、先ほどの例だと、「ユーザーの名前だけ取得するエンドポイント」や「ユーザー情報と投稿情報を取得するエンドポイント」を作成するということです。
こうすれば、必要なときに必要なデータだけを取得することができます。
ただ、この方法には大きな問題があります。
それは、エンドポイントが増えすぎて管理が難しくなるということです。
それこそ複雑な仕様のアプリケーションだと、エンドポイントが数百になることもあるかもしれません。
そんなアプリは誰も管理したくないでしょう。
さらに、必要なデータのユースケースが増えるたびに、エンドポイントを新設しないといけないため、その分の改修コストも加算されてしまいます。
このようにRESTには多くの課題が指摘されていました。
そんな中登場したのが、RESTの課題の多くを解決するとされているGraphQLです。
GraphQLの歴史
まずはGraphQLの歴史を簡単に解説します。
GraphQLは前述のようなRESTの課題を解決するために、Facebookによって開発されました。
2012年2月に最初のプロトタイプが完成し、同年8月頃にFacebookのiOSアプリケーションに組み込まれたそうです。
その後、2015年にGraphQLの仕様を公開し、現在では、FacebookのほぼすべてのサービスでGraphQLが利用されています。
GraphQLは、Facebook以外にも、IBMやAirbnb、GitHub、Shopifyをはじめとして多くの企業で採用されています。
GraphQLのメリット(どうRESTの課題を解消するか)
GraphQLには次のようなメリットがあり、RESTの課題の多くを解決することができます。
- 必要なデータだけを取得できる
- 関連する情報も一つのクエリで取得可能
- 直感的に記述できるので分かりやすい
- エンドポイントの管理が不要
それぞれサクッと解説していきます。
必要なデータだけを取得できる
GraphQLは、RESTのように対象のエンドポイントに対してGETリクエストを送ってデータを取得するのではなく、必要なデータカラムを含んだクエリをPOSTすることでデータを取得します。
例えばユーザー情報(年齢・名前・性別・メールアドレス・自己紹介)の中から、名前のみを取得したい場合、以下のようなクエリをPOSTすることで、名前のみを取得することができます。
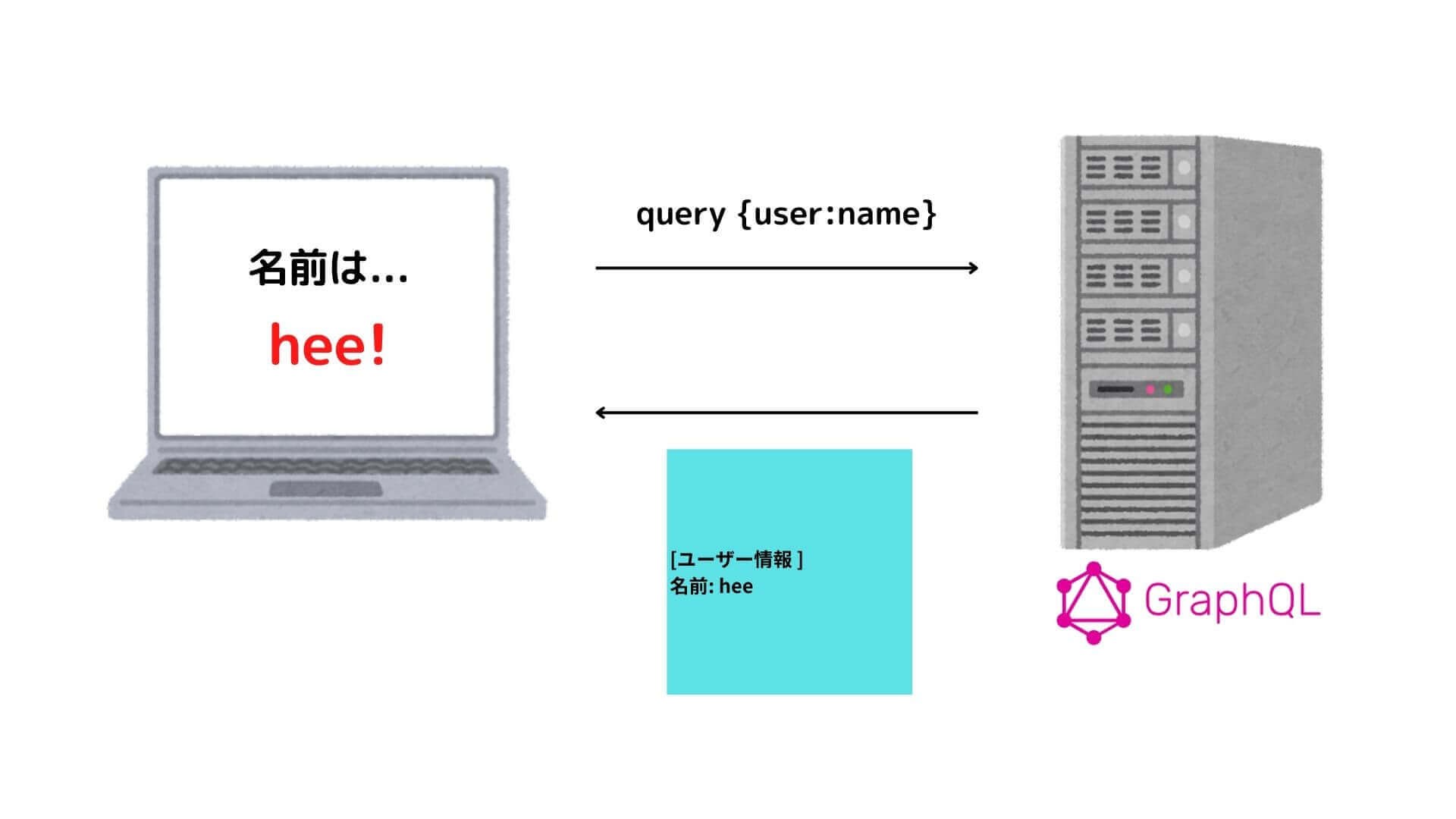
名前以外の情報も取りたい場合は以下のようにPOSTすればOKです。(簡略化のためqueryの厳密な記述方法は無視しています)
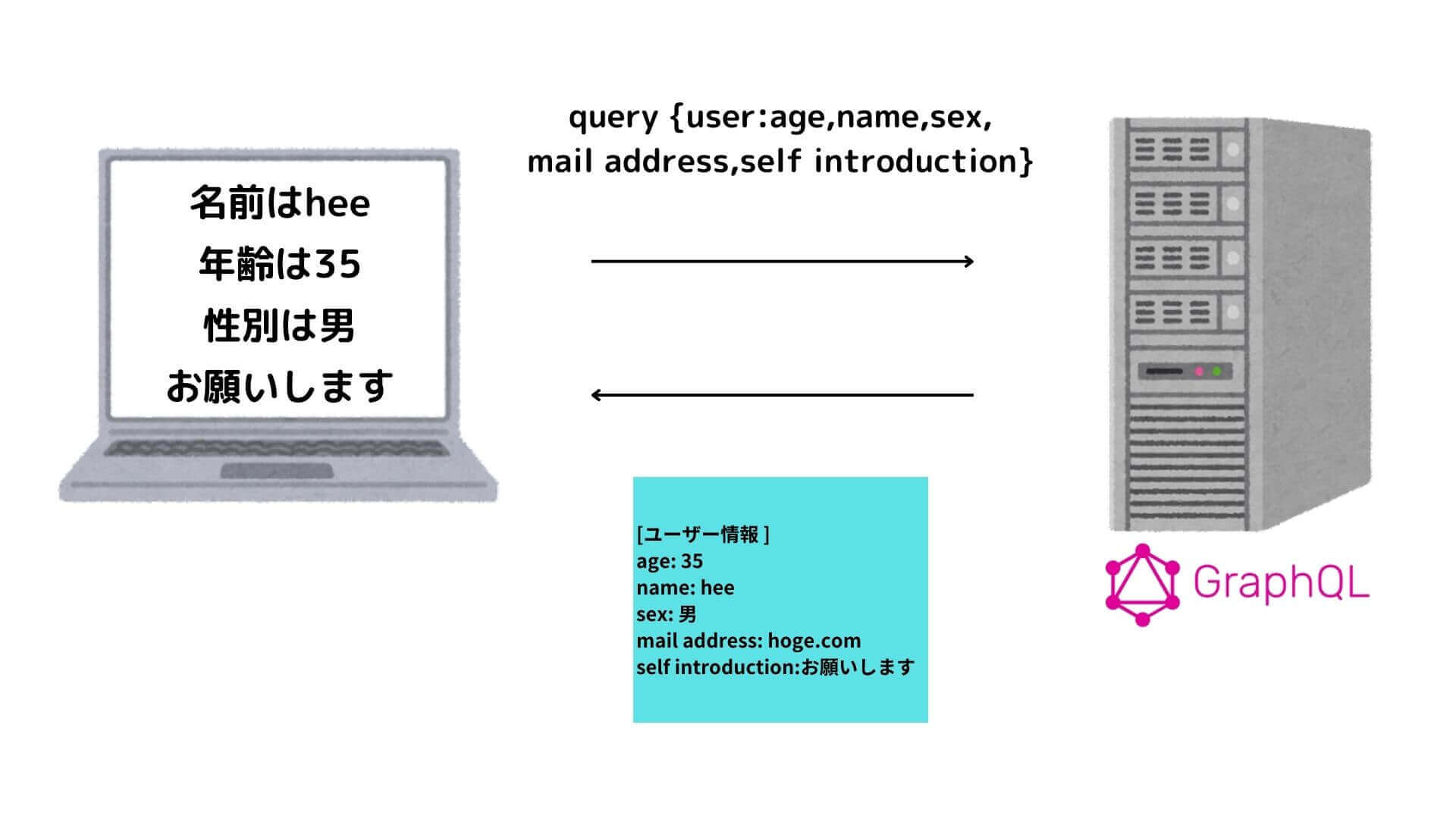
このような柔軟性のある仕様により、「必要なときに必要なデータのみを取得」することができるため、RESTの課題であった「オーバーフェッチング」や「アンダーフェッチング」は解消されます。
関連する情報も一つのクエリで取得可能
例えばUserに紐付く投稿(Post)情報を取りたい場合、GraphQLのスキーマにリレーション関係を定義することで、以下のように一つのクエリで取得することができます。
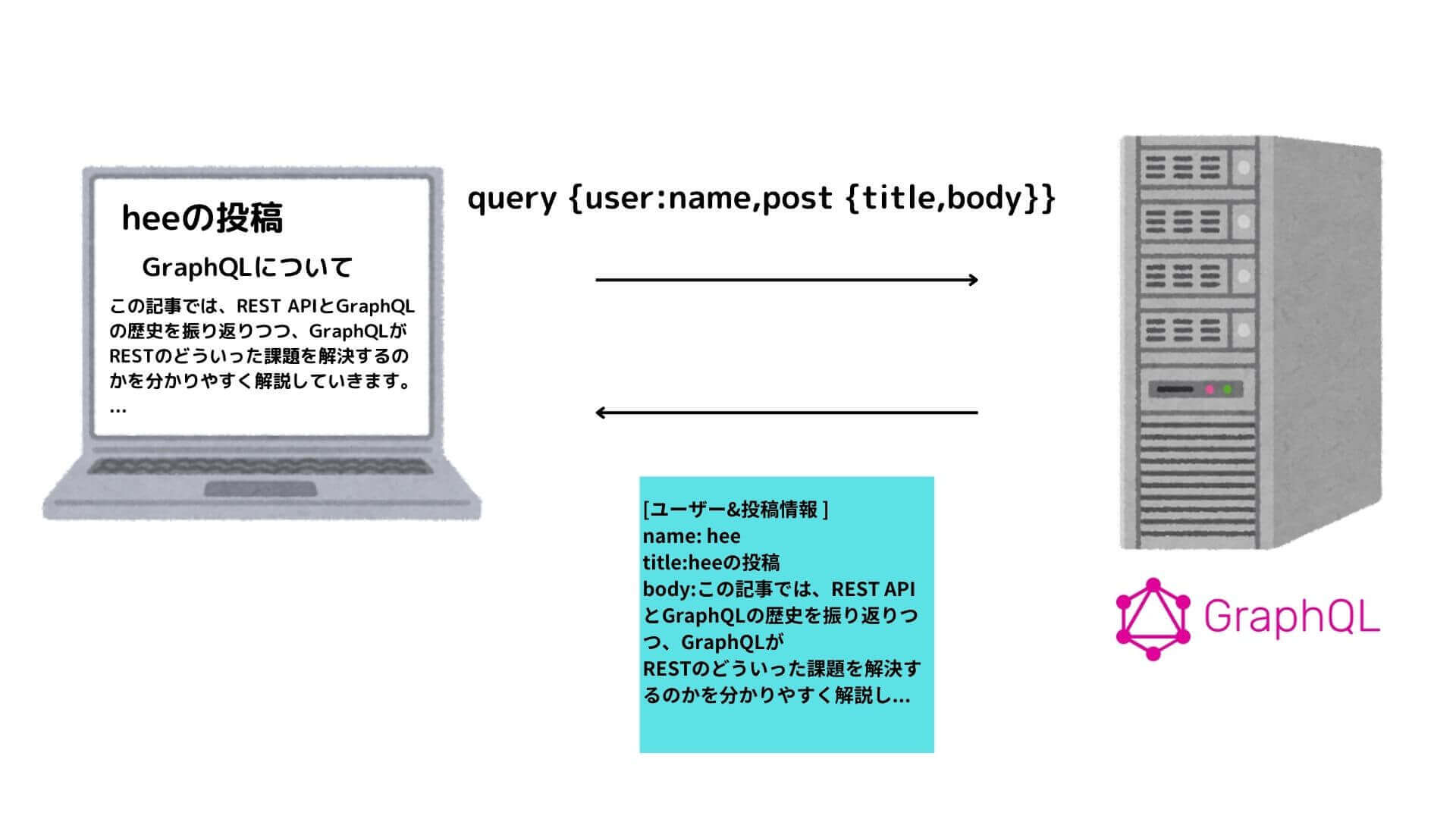
前述の「必要なデータだけを取得できる」も含めて、複雑なデータ構造に対してもこのような柔軟性の高い表現ができる点がGraphQLの最大のメリットと言っていいでしょう。
また、サーバー側の構造を変更することなく柔軟にクライアント(フロント)側で取得するデータ構造を変更できるため、A/Bテスト等の小さな変更が行いやすいのもメリットの一つです。
直感的に記述できるので分かりやすい
GraphQLは、RESTのように「このエンドポイント叩けば何が返るのだろう?」を考える必要がなく、クエリ自体に欲しい情報をそのまま定義できるので、非常に直感的で記述しやすいです。
最初は慣れずに苦労することもあるとは思いますが、慣れたら非常に使いやすいツールとなるでしょう。
エンドポイントの管理が不要
RESTの場合はユースケースが増えればエンドポイントも増えていきます。
しかし、GraphQLの場合はそもそも一つのエンドポイントしか存在しておらず、そのエンドポイントに対してPOSTリクエストを送ることでデータを取得します。
そのため、GraphQLを使用することで、RESTの面倒なエンドポイント管理からは完全に解放されるでしょう。
これら以外にも、RESTにはない強力な型システムや充実した周辺エコシステムなど、GraphQLを用いた開発のしやすさは年々向上していると言えるでしょう。
特に型システムはアプリケーションの堅牢性に繋がるので大きなメリットの一つと言えます。
GraphQLのデメリットについて
見事にRESTの課題を克服したGraphQLですが、デメリットも存在します。
- 学習コストの高さ
- セキュリティ面やN+1など、気を付けないといけない点が多い
学習コストの高さ
一つ目は学習コストが高い点です。
単純にRESTとは全く異なるアプローチを取っているAPIなので、概念レベルから学習する必要があります。
さらに、周辺ツールの使い方等も含めて学ぶ必要があるので、学習コストはそれなりに高いでしょう。
ただ、個人的には、基礎的な概念さえ掴めることができれば、あとは実際に使っていく中で慣れていくことは可能なのかなと思っています。
セキュリティ面やN+1など、気を付けないといけない点が多い
GraphQLにはcomplexityやN+1問題など、セキュリティやパフォーマンスおよびキャッシュ等の観点で考慮しないといけない点が多いです。
そのため、ある程度の経験がないとそれら全てに適切に対処するのは難しいでしょう。
また、まだGraphQL自体の歴史が浅いことから、それらに対するソリューションや事例が少ないのも課題の一つです。(これについては時間が解決してくれるとは思いますが。。)
REST APIとGraphQLの歴史を分かりやすくまとめてみる:おわりに
最後にまとめをもう一度貼っておきます。
- REST以前のAPIの歴史
- 1960年代にRPCが登場
- 1999年に登場したのがSOAP
- その後に登場したのがREST
- RESTの課題
- 不要なデータまで取得する
- 必要なデータを得るために何度もRequestを送る必要がある
- エンドポイントが増え続けるため管理が大変
- GraphQLの歴史
- GraphQLはRESTの課題を解決するためにFacebookによって開発された
- 2015年にオープンソース化
- GraphQLのメリット
- 一つのクエリで過不足なくデータを取得できる
- 欲しいデータを直接指定できるので分かりやすい(記述しやすい)
- エンドポイントの管理が不要
- 強力な型システム
- GraphQLのデメリット
- 学習コストが高い
- complexityやN+1問題など、適切な対処ができないとセキュリティやパフォーマンス面で落とし穴になる場合がある
- RESTに比べて歴史が浅いためまだ情報は不足している
最後まで読んでいただきありがとうございました。
この記事がREST APIとGraphQLの歴史を知る上で少しでも参考になっていれば幸いです。













